반응형

Databricks 에서
S3에 파일을 가져와 Table을 생성해본다.
1. AWS 역할(role) 생성
1.1 역할 생성을 위해, managed(account) console 에서 Account ID를 확인한다.

1.2 AWS 콘솔에서 IAM으로 이동. [역할] - [역할 만들기]

- 다른 AWS 계정에는 databricks account id 입력
- 외부 ID에는, databricks account id 입력

이름을 지정하고 일단 저장한다.

생성한 역할로 들어간다.
[인라인 정책 생성] 으로 이동한다.
JSON 에 아래와 같이 정보를 입력한다.
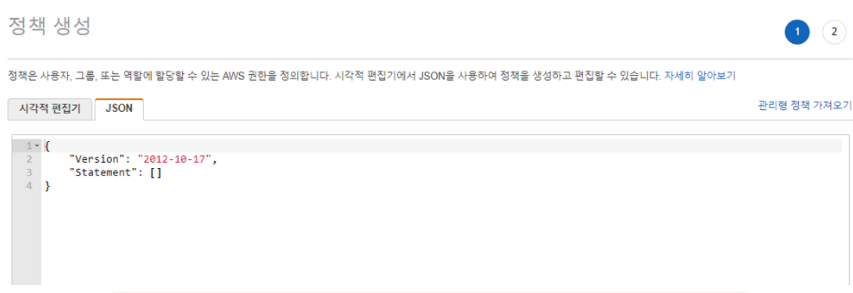
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:GetLifecycleConfiguration",
"s3:PutLifecycleConfiguration"
],
"Resource": [
"arn:aws:s3:::bucket_name" <-- 사용할 S3 bucket ARN
]
},
{
"Action": [
"sts:AssumeRole"
],
"Resource": [
"arn:aws:iam::accountid:role/wstest" <-- 해당 role ARN
],
"Effect": "Allow"
}
]
}
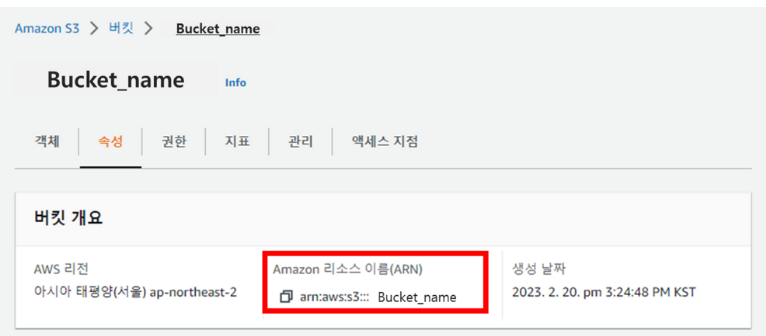
Resource 의 S3의 ARN은 아래정보를 복사한다.
정책명을 입력하고, 저장한다
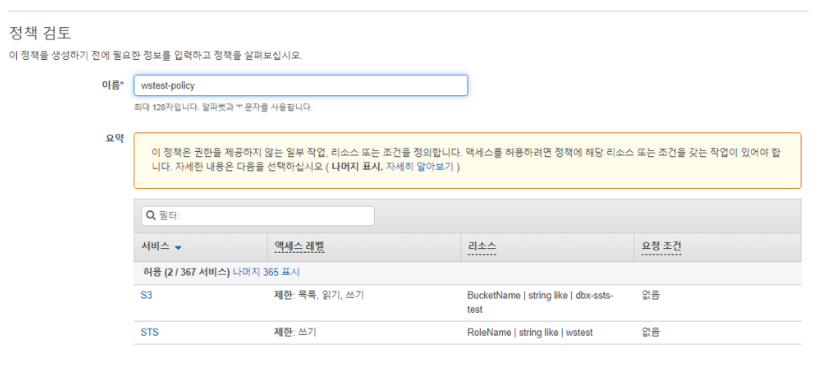
2. Databricks의 Storage Credential 생성
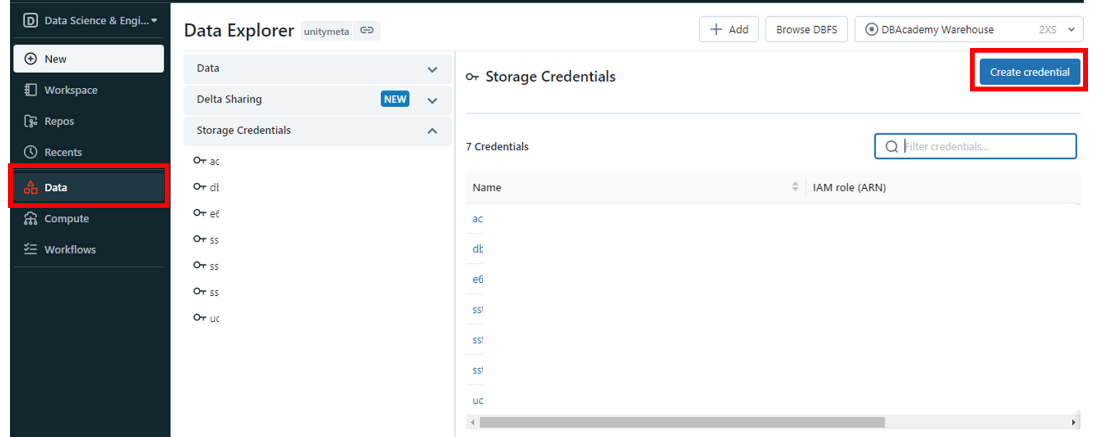
위에서 생성한 역할의 ARN을 등록한다.
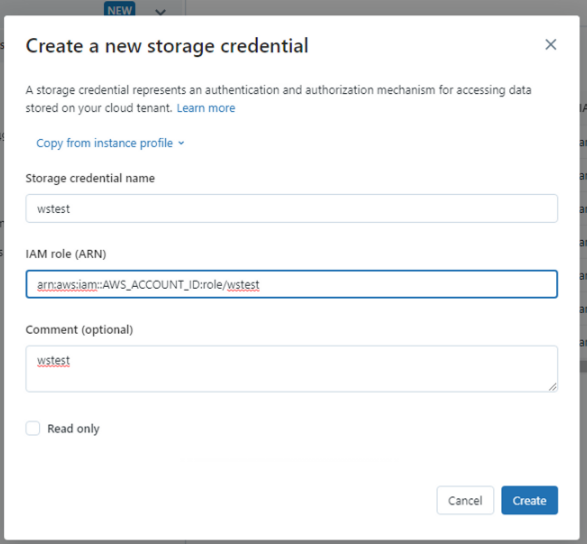
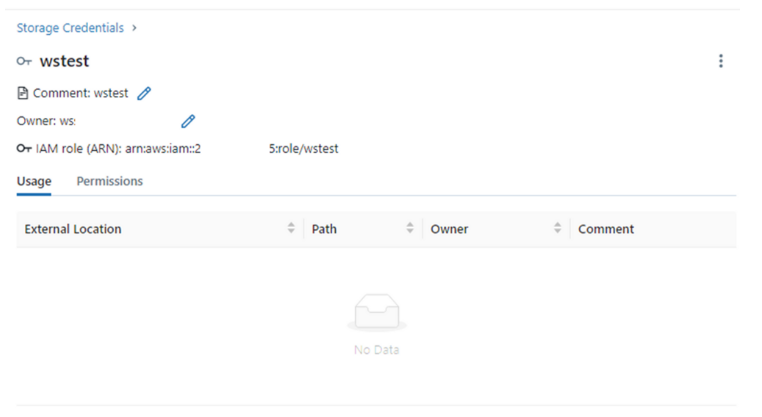
3. Databricks의 External location 생성
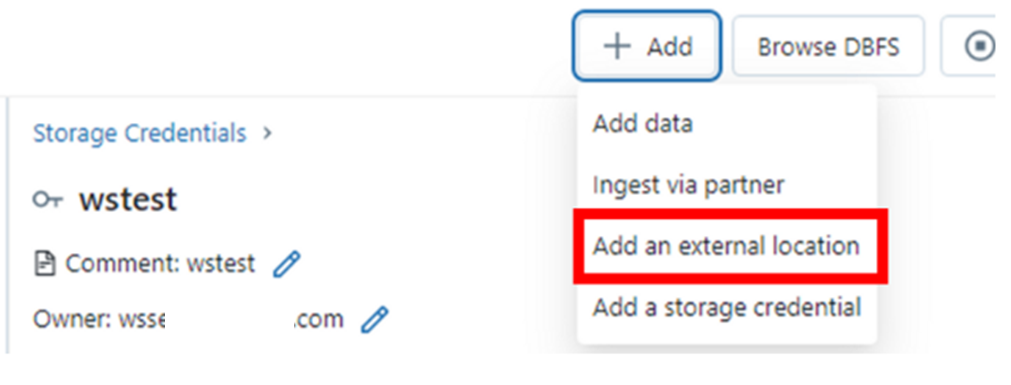
S3 bucket 경로와,
생성한 Storage credential을 입력(선택) 한다.
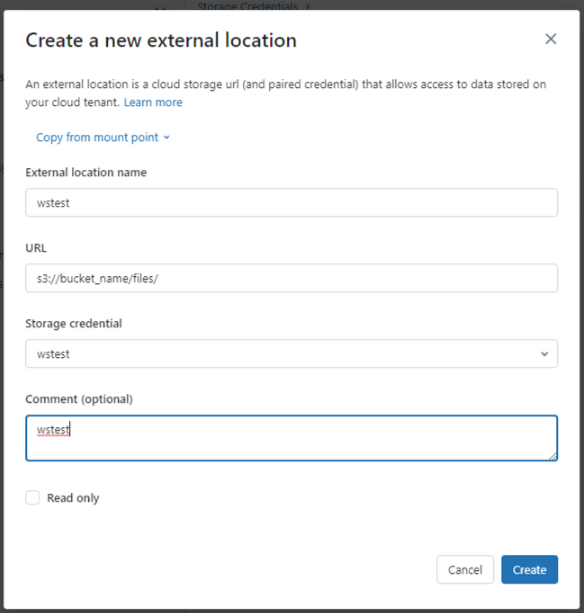
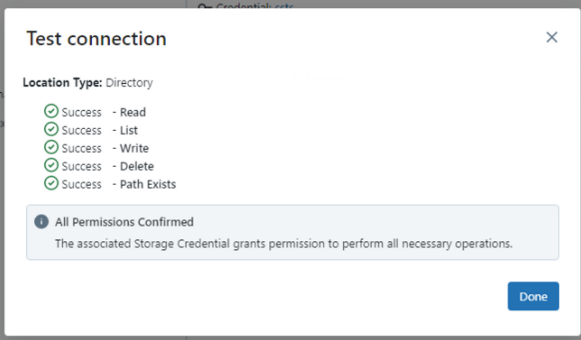
[Test connection] 을 통해 S3 접근을 확인한다.

S3
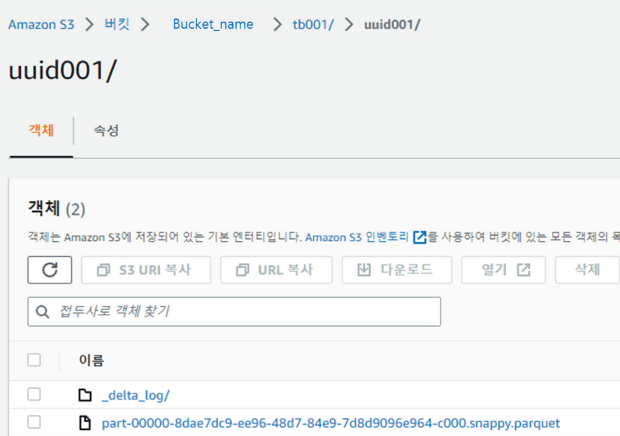
4. Databricks에서 Catalog, S3로 Table 생성
%sql
CREATE CATALOG IF NOT EXISTS `catalog_name`
%sql
CONVERT TO DELTA parquet.`s3://bucket_name/tb001/uuid001/`
%sql
CREATE TABLE `catalog_name`.default.test_tbl LOCATION 's3://bucket_name/tb001/uuid001'
%sql
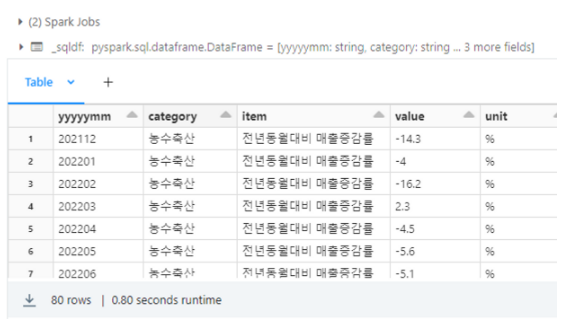
select * from `catalog_name`.default.test_tbl
- 삭제
%sql
DROP TABLE IF EXISTS `catalog_name`.default.test_tbl
dbutils.fs.rm('s3://bucket_name/tb001/uuid001/_delta_log', True)
반응형
'AWS' 카테고리의 다른 글
| AWS DMS로 가져온 Transaction 정보를 이용해 databricks delta table 에서 merge into 하기 (3) | 2023.03.06 |
|---|---|
| AWS DMS(Data Migration Service)를 사용하여 Aurora PostgreSQL 를 AWS S3에 날짜 기준으로 파티셔닝 하여 적재 (0) | 2023.02.23 |
| AWS Glue로 S3 에 저장된 parquet 파일 읽어보기 (0) | 2023.01.05 |
| AWS Glue에서 ngdbc 를 이용해 SAP HANA CLOUD 데이터를 S3에 저장하기 (0) | 2023.01.04 |
| AWS Glue에서 hdbcli 를 이용해 SAP BW 데이터를 S3에 저장하기 (0) | 2023.01.04 |