반응형

AWS DMS(Data Migration Service)를 사용하여 Aurora PostgreSQL 를 AWS S3에 날짜 기준으로 파티셔닝 하여 적재
AWS DMS 를 사용해 Aurora PostgreSQL → AWS S3로 파티셔닝 해 적재해본다. 1. 복제 인스턴스 생성 VPC와 subnetgroup을 잘 선택하여 생성한다. 생성 시 ‘퍼블릭 액세스 가능’ 가 선택되어야 S3 접근이 가능
whiseung.tistory.com
databricks 에서 Storage Credential 과 External Location 등록해 AWS S3를 Table로 생성하기.
Databricks 에서 S3에 파일을 가져와 Table을 생성해본다. 1. AWS 역할(role) 생성 1.1 역할 생성을 위해, managed(account) console 에서 Account ID를 확인한다. 1.2 AWS 콘솔에서 IAM으로 이동. [역할] - [역할 만들기]
whiseung.tistory.com
💡 AWS DMS를 통해 Aurora PostgreSQL 에서 AWS S3로 가져온 transaction 정보를
Databricks Delta Table에서 반영한다.
1. CDC 된 parquet 파일을 dataframe 으로 불러옴
import datetime
now_date = datetime.datetime.now()
exec_date = datetime.datetime.strftime(now_date, '%Y/%m/%d')
cdc_s3_full_path = f"s3://bucket_name/postgresql_transaction/schema_name/table_name/{exec_date}"
df = spark.read.format("parquet").option("header", "false").load(cdc_s3_full_path)
from pyspark.sql.functions import col
sortDF = df.sort(col("transact_seq").asc())
sortDF.show()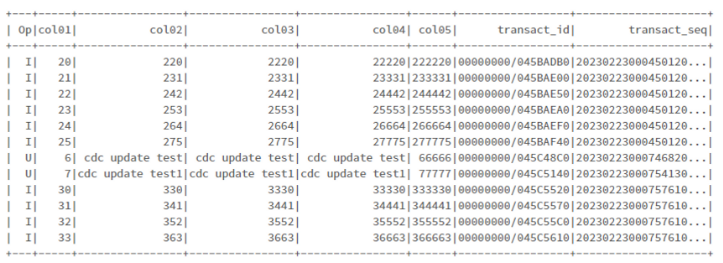
2. pk 별로 partition by 진행, pk의 max transaction_seq 구하기
import sys
from pyspark.sql.window import Window
from pyspark.sql.functions import max
windowSpec = Window.partitionBy(df.col01).orderBy(df.transact_seq).rangeBetween(-sys.maxsize, sys.maxsize)
maxSeqDF = df.withColumn("max_seq", max(col("transact_seq")).over(windowSpec))
maxSeqDF.show()
3. merge 할 최종 dataframe 생성
insertDF = maxSeqDF.filter("transact_seq=max_seq").filter("Op='I'")
updateDF = maxSeqDF.filter("transact_seq=max_seq").filter("Op IN ('U', 'D')")
finalDF = insertDF.unionAll(updateDF)
finalDF.show()

4. dataframe을 테이블로 만들기
finalDF.createOrReplaceTempView("cdcData")
spark.sql("select * from cdcData").show()

5. merge into 문 수행
5.1 sql
%sql
MERGE INTO `catalog`.default.test_tbl_003 as T
USING (SELECT Op, col01, col02, col03, col04, col05 FROM cdcData) s
ON t.col01 = s.col01
WHEN MATCHED AND s.Op = 'D' THEN DELETE
WHEN MATCHED AND s.OP = 'U' THEN UPDATE SET t.col02 = s.col02, t.col03 = s.col03, t.col04 = s.col04, t.col05 = s.col05
WHEN NOT MATCHED AND s.OP = 'I' THEN INSERT ( col01, col02, col03, col04, col05) VALUES ( s.col01, s.col02, s.col03, s.col04, s.col05)5.2 spark
spark.sql("MERGE INTO `catalog`.default.test_tbl_003 as T \\
USING (SELECT Op, col01, col02, col03, col04, col05 FROM cdcData) s \\
ON t.col01 = s.col01 \\
WHEN MATCHED AND s.Op = 'D' THEN DELETE \\
WHEN MATCHED AND s.OP = 'U' THEN UPDATE SET t.col02 = s.col02, t.col03 = s.col03, t.col04 = s.col04, t.col05 = s.col05 \\
WHEN NOT MATCHED AND s.OP = 'I' THEN INSERT ( col01, col02, col03, col04, col05) VALUES ( s.col01, s.col02, s.col03, s.col04, s.col05) \\
").show()
6. 확인
spark.sql("SELECT * FROM `ssts-test`.default.test_tbl_003 ORDER BY cast(col01 as int) DESC").show()

반응형
'AWS' 카테고리의 다른 글
| databricks 에서 Storage Credential 과 External Location 등록해 AWS S3를 Table로 생성하기. (0) | 2023.02.27 |
|---|---|
| AWS DMS(Data Migration Service)를 사용하여 Aurora PostgreSQL 를 AWS S3에 날짜 기준으로 파티셔닝 하여 적재 (0) | 2023.02.23 |
| AWS Glue로 S3 에 저장된 parquet 파일 읽어보기 (0) | 2023.01.05 |
| AWS Glue에서 ngdbc 를 이용해 SAP HANA CLOUD 데이터를 S3에 저장하기 (0) | 2023.01.04 |
| AWS Glue에서 hdbcli 를 이용해 SAP BW 데이터를 S3에 저장하기 (0) | 2023.01.04 |