
kosis openAPI를 AWS Lambda를 이용해 호출해보는것까지 해보았다.
Lambda가 아닌 AWS Glue를 이용해 데이터를 S3에 저장하는 기능을 구현해본다.
Glue 서비스로 이동한다.
Jobs에 Python script editor를 선택하고 [Create]를 클릭한다.

[Script] 탭에, 작성한 python code를 붙여넣고,

[Job Detail] 탭으로 이동하여, Job 이름을 설정하고,

그리고 IAM Role을 설정해준다.

IAM이 없으면 아래와같이 생성해준다.
AWS Glue 를 사용하기 위한 IAM 생성
AWS Glue를 사용하려고하는데, IAM을 선택해야 실행할수 있엇다. 그래서 IAM을 만들러 왔다. [IAM] - [역할] 로 이동. [역할 만들기] 클릭 신뢰할수 있는 엔티티 유형 중 [AWS 서비스] 를 선택하고, 다른 AW
whiseung.tistory.com
import json
import io
import boto3
import pandas as pd
from urllib.request import urlopen
from datetime import datetime
ACCESS_KEY = 'access_key'
SECRET_KEY = 'secret_key'
def getApiUploadS3(apiUrl, s3Url, s3Path, tempFileName):
with urlopen(apiUrl) as url:
json_file = url.read()
py_json = json.loads(json_file.decode('utf-8'))
data = []
for i, v in enumerate(py_json):
if i == 0 :
print(f"Title : {v['TBL_NM']}")
value = []
value.append(v['PRD_DE'])
value.append(v['C1_NM'])
value.append(v['ITM_NM'])
value.append(v['DT'])
value.append(v['UNIT_NM'])
data.append(value)
df = pd.DataFrame(data)
df.columns = ['yyyyymm', 'category', 'item', 'value', 'unit']
df.to_parquet(s3Url + s3Path + tempFileName
, engine='pyarrow'
, index=False
)
return s3Path + tempFileName
if __name__ == "__main__":
apiUrl = "https://kosis.kr/openapi/statisticsData.do?method=getList&apiKey=apiKey&format=json&jsonVD=Y&userStatsId=whiseung/115/DT_11523_400/2/1/20221123094346&prdSe=M&newEstPrdCnt=10"
bucketName = 'bucket_name'
s3Path = 'parquet_files/'
thisTime = datetime.today().strftime('%Y%m%d%H%M%S')
tempFileName = f'KOSIS_DT_11523_400_{thisTime}.parquet'
resultFileName = getApiUploadS3(apiUrl, f's3://{bucketName}/', s3Path, tempFileName)
print(f'### Parquet file created! {resultFileName}')
실행하게되면, 아래와 같은 에러메세지가 발생한다.
ImportError: pyarrow is required for parquet support
Glue 3.0 은 python 3.9 버전이고,
Glue 1.0 은 python 3.6 버전이므로
3.6버전의 라이브러리를 다운 받아야 한다.
pyarrow 라이브러리를 whl 파일로 s3에 업로드하고,
[Job details] 의 Python library path 에 s3에 올린 파일들 경로를 적어준다.
s3://bucket_name/pyarrow-6.0.0-cp36-cp36m-manylinux_2_12_x86_64.manylinux2010_x86_64.whl
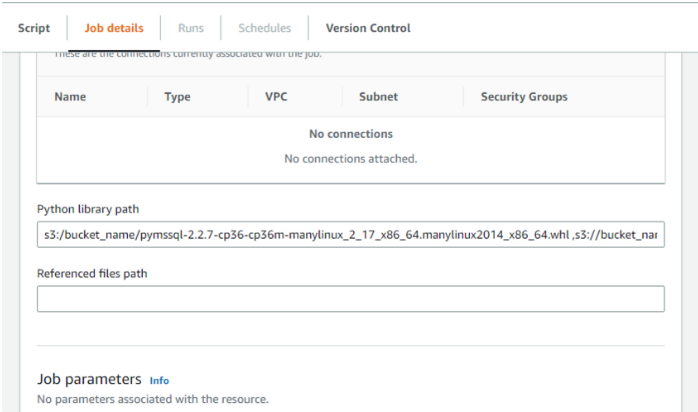
다시 실행해본다. 또 에러가 발생한다.
ImportError: The s3fs library is required to handle s3 files
s3fs 또한 다운받아서 s3에 올려주고,
Python library path 에 추가해준다.
s3://bucket_name/pyarrow-6.0.0-cp36-cp36m-manylinux_2_12_x86_64.manylinux2010_x86_64.whl, s3://bucket_name/s3fs-0.4.2-py3-none-any.whl
정상적으로 실행되는것을 확인할 수 있다.
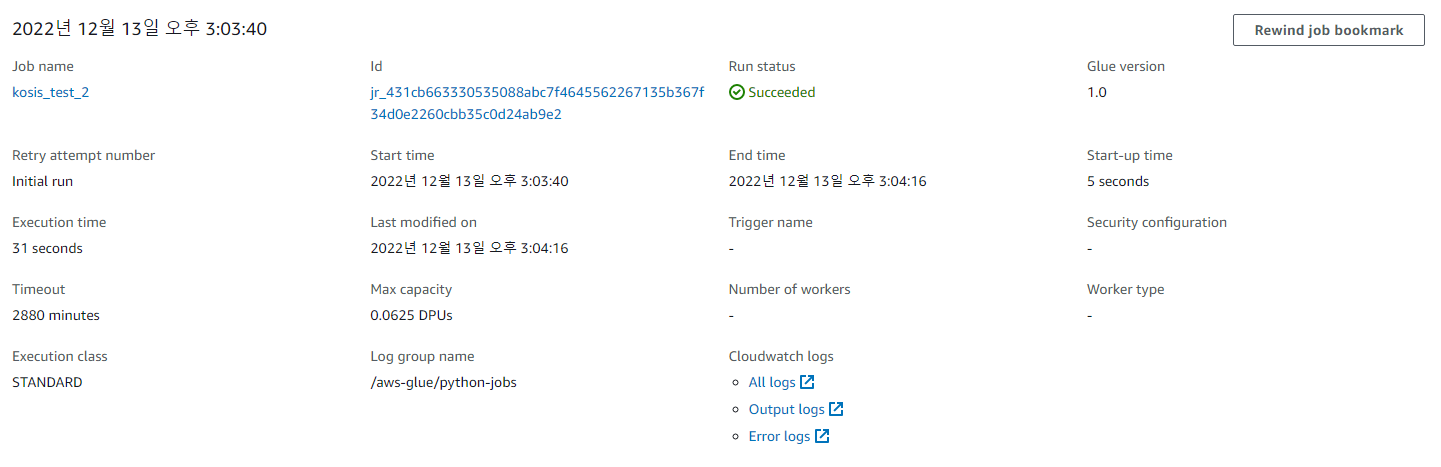
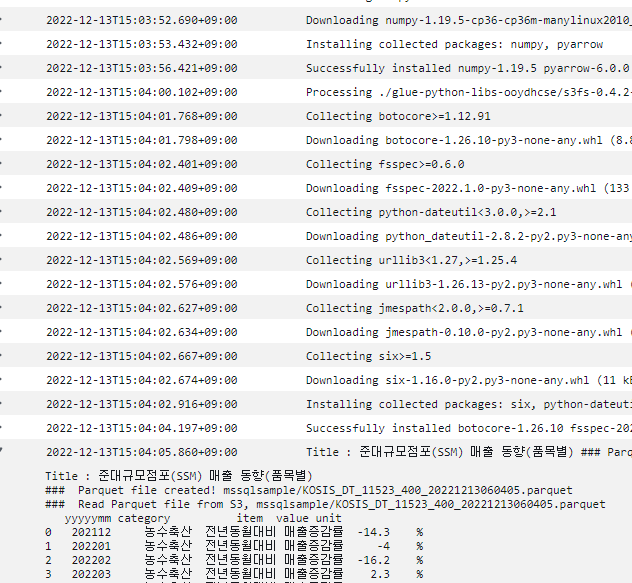
'AWS' 카테고리의 다른 글
| AWS Glue에서 Spark를 이용해 MSSQL 데이터를 S3에 저장하기 (0) | 2022.12.26 |
|---|---|
| AWS Glue에서 pymssql 을 이용해 MSSQL 데이터를 S3에 저장하기 (0) | 2022.12.26 |
| AWS Glue 를 사용하기 위한 IAM 생성 (0) | 2022.12.13 |
| API batch 실행을 위해 EventBridge 로 Schedule 생성하여 AWS Lambda 호출 (0) | 2022.12.12 |
| KOSIS openAPI 호출을 위한 AWS Lambda 생성 (0) | 2022.12.09 |