반응형

KOSIS openAPI 를 가져왔으니, 이를 AWS S3에 올리려고 한다.
일단 S3에 접근할수 있는 IAM 자격정보를 가져온다
[IAM] - [액세스 관리] - [사용] 로 이동한다.

사용자를 클릭하고, [보안 자격 증명] 으로 이동한 뒤 [엑세스 키 만들기] 를 클릭한다.
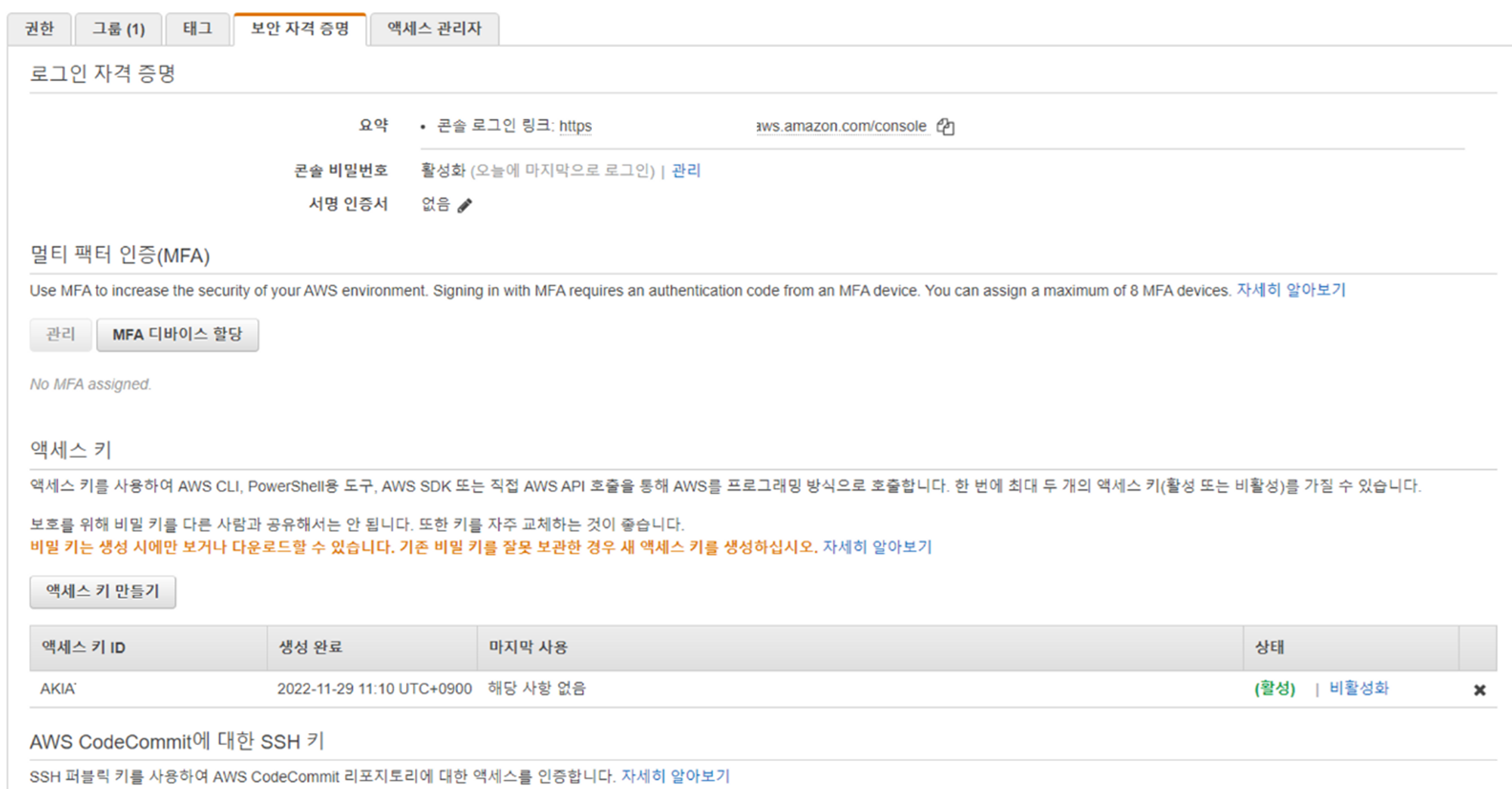
액세스키를 만들고,
엑세스 키 ID 와,
비밀 액세스 키 를 이용해 python에서 S3에 접근한다.

로컬에, parquet 파일 만들기 (SDMX)
import pandas as pd
import requests
from bs4 import BeautifulSoup
open_url = "https://kosis.kr/openapi/statisticsBigData.do?method=getList&apiKey=api_key&format=sdmx&userStatsId=whiseung/135/DT_135N_1A001A/3/1/20221124104644&type=StructureSpecific&prdSe=Y&newEstPrdCnt=1&version=v2_1"
res = requests.get(open_url)
soup = BeautifulSoup(res.content, 'html.parser')
datalist = soup.find_all('series')
data = []
for item in datalist:
value = []
value.append(item.get('item'))
value.append(item.get('c_a01'))
value.append(item.get('unit'))
subitem = item.find('obs')
value.append(subitem.get('time_period'))
value.append(subitem.get('obs_value'))
data.append(value)
df = pd.DataFrame(data)
df.columns = ['item', 'category', 'unit', 'date', 'value']
df.head()
print(df)
df.to_parquet('data3.parquet', engine='pyarrow', index=False)로컬의 parquet 파일을 S3 upload
import boto3
ACCESS_KEY = 'access_key'
SECRET_KEY = 'secret_key'
bucket_name = 'bucket_name'
region = 'ap-northeast-2'
prefix = 'prefix/'
s3 = boto3.client('s3',aws_access_key_id=ACCESS_KEY, aws_secret_access_key=SECRET_KEY)
file_name = 'data3.parquet'
s3.upload_file(file_name, bucket_name, file_name)결과
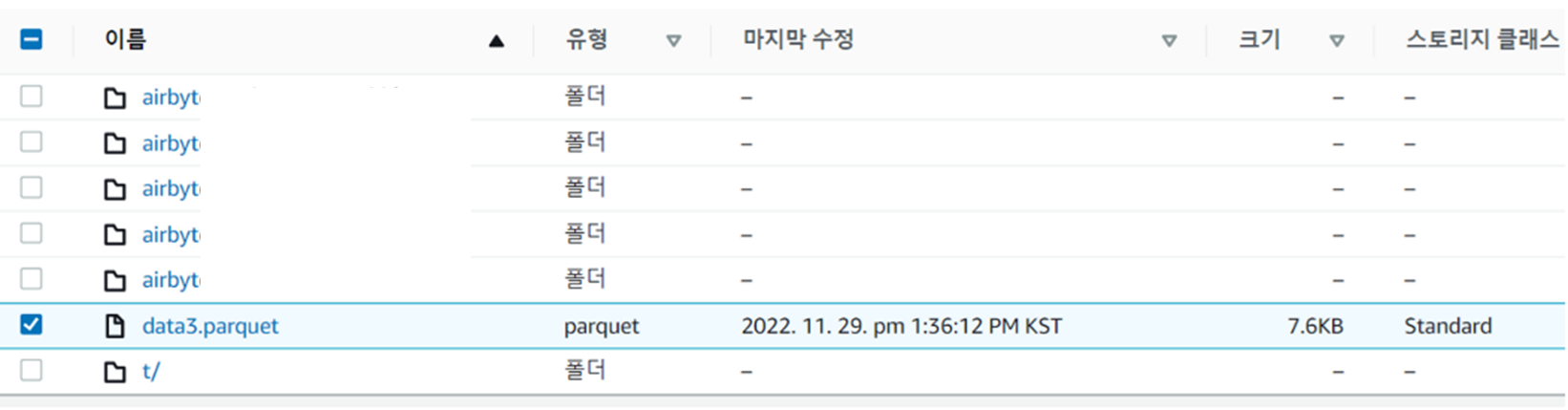
S3 의 리스트 조회
import boto3
ACCESS_KEY = 'access_key'
SECRET_KEY = 'secret_key'
bucket_name = 'bucket_name'
region = 'ap-northeast-2'
prefix = ''
s3 = boto3.client('s3',aws_access_key_id=ACCESS_KEY, aws_secret_access_key=SECRET_KEY)
response = s3.list_buckets()
obj_list = s3.list_objects(Bucket=bucket_name, Prefix=prefix)
contens_list = obj_list['Contents']
for content in contens_list:
print(content)PS C:\\workspace\\api> & C:/Users/서휘승/AppData/Local/Microsoft/WindowsApps/python3.8.exe c:/workspace/api/getS3.py
{'Key': 'data3.parquet', 'LastModified': datetime.datetime(2022, 11, 29, 4, 36, 12, tzinfo=tzutc()), 'ETag': '"etag"', 'Size': 7798, 'StorageClass': 'STANDARD', 'Owner': {'ID': 'id'}}S3 의 parquet file 읽기
import boto3
import io
import pandas as pd
ACCESS_KEY = 'access_key'
SECRET_KEY = 'secret_key'
bucket_name = 'bucket_name'
s3 = boto3.client('s3',aws_access_key_id=ACCESS_KEY, aws_secret_access_key=SECRET_KEY)
obj = s3.get_object(Bucket=bucket_name, Key='data3.parquet')
result = pd.read_parquet(io.BytesIO(obj['Body'].read()))
print(result)PS C:\\workspace\\api> & C:/Users/서휘승/AppData/Local/Microsoft/WindowsApps/python3.8.exe c:/workspace/api/getS3.py
item category unit date value
0 16135A1 A001 14STD03818 2020 1714579
1 16135A3 A001 14STD03818 2020 1399428
2 16135A5 A001 14STD04548 2020 1638387
3 16135A1 A002 14STD03818 2020 1044438
4 16135A3 A002 14STD03818 2020 767742
.. ... ... ... ... ...
511 16135A3 A244 14STD03818 2020 2475
512 16135A5 A244 14STD04548 2020 3000
513 16135A1 A300 14STD03818 2020 668
514 16135A3 A300 14STD03818 2020 657
515 16135A5 A300 14STD04548 2020 676
[516 rows x 5 columns]
PS C:\\workspace\\api>
로컬에 파일 저장하지 않고, 바로 S3에 저장하도록 구현 (json)
import json
import io
import boto3
import pandas as pd
from urllib.request import urlopen
from datetime import datetime
ACCESS_KEY = 'access_key'
SECRET_KEY = 'secret_key'
def getApiUploadS3(apiUrl, s3Url, s3Path, tempFileName):
with urlopen(apiUrl) as url:
json_file = url.read()
py_json = json.loads(json_file.decode('utf-8'))
data = []
for i, v in enumerate(py_json):
if i == 0 :
print(f"Title : {v['TBL_NM']}")
value = []
value.append(v['PRD_DE'])
value.append(v['C1_NM'])
value.append(v['ITM_NM'])
value.append(v['DT'])
value.append(v['UNIT_NM'])
data.append(value)
df = pd.DataFrame(data)
df.columns = ['yyyyymm', 'category', 'item', 'value', 'unit']
df.to_parquet(s3Url + s3Path + tempFileName
, engine='pyarrow'
, index=False
, storage_options={"key": ACCESS_KEY,
"secret": SECRET_KEY }
)
return s3Path + tempFileName
if __name__ == "__main__":
apiUrl = "https://kosis.kr/openapi/statisticsData.do?method=getList&apiKey=api_key&format=json&jsonVD=Y&userStatsId=whiseung/115/DT_11523_400/2/1/20221123094346&prdSe=M&newEstPrdCnt=3"
bucketName = 'bucket_name'
s3Path = 'parquet/'
thisTime = datetime.today().strftime('%Y%m%d%H%M%S')
tempFileName = f'KOSIS_DT_11523_400_{thisTime}.parquet'
resultFileName = getApiUploadS3(apiUrl, f's3://{bucketName}/', s3Path, tempFileName)
print(f'### Parquet file created! {resultFileName}')
다음엔, 해당 python 파일을 lambda에서 실행해야겠다.
반응형
'AWS' 카테고리의 다른 글
| AWS Glue에서 pymssql 을 이용해 MSSQL 데이터를 S3에 저장하기 (0) | 2022.12.26 |
|---|---|
| KOSIS openAPI 를 AWS Glue 에서 실행해보기 (1) | 2022.12.13 |
| AWS Glue 를 사용하기 위한 IAM 생성 (0) | 2022.12.13 |
| API batch 실행을 위해 EventBridge 로 Schedule 생성하여 AWS Lambda 호출 (0) | 2022.12.12 |
| KOSIS openAPI 호출을 위한 AWS Lambda 생성 (0) | 2022.12.09 |